本文共 4782 字,大约阅读时间需要 15 分钟。
论文名称:Profile Consistency Identification for Open-domain Dialogue Agents
论文作者:宋皓宇,王琰,张伟男,赵正宇,刘挺,刘晓江
原创作者:宋皓宇
论文链接:https://www.aclweb.org/anthology/2020.emnlp-main.539.pdf
资源地址:https://github.com/songhaoyu/KvPI
转载须标注出处:哈工大SCIR
保持一致的角色属性是对话系统自然地与人类进行交流的关键因素之一。现有的关于提高属性一致性的研究主要探索了如何将属性信息融合到对话回复中,但是很少有人研究如何理解、识别对话系统的回复与其属性之间的一致性关系。
在这项工作中,为了研究如何识别开放域对话的属性一致性,我们构建了一个大规模的人工标注数据集KvPI,该数据集包含了超过11万组的单轮对话及其键值对属性信息。对话回复和键值对属性信息之间的一致性关系是通过人工进行标注的。在此基础上,我们提出了一个键值对结构信息增强的BERT模型来识别回复的属性一致性。该模型的准确率相较于强基线模型获得了显著的提高。更进一步,我们在两个下游任务上验证了属性一致性识别模型的效果。实验结果表明,属性一致性识别模型有助于提高开放域对话回复的一致性。
本期AI TIME PhD直播间,我们有幸邀请到了该论文的作者,哈尔滨工业大学的博士生宋皓宇,为大家分享这项研究工作!

宋皓宇:哈尔滨工业大学社会计算与信息检索研究中心(SCIR)博士三年级研究生,导师为刘挺教授。主要研究方向为开放域对话系统。相关研究成果发表在ACL、EMNLP、AAAI、IJCAI等会议上。

1. 简介
一致性问题是当前开放域对话面临的主要问题之一。已有的研究工作主要探索了如何将属性信息融合到对话回复中[1,2,3,4],但是很少有人研究如何理解、识别对话系统的回复与其预设属性之间的一致性关系。为了研究这一问题,在这项工作中我们构建了一个大规模的人工标注数据集KvPI(Key-value Profile consistency Identification)。该数据集包含了超过11万组的单轮对话及其键值对属性信息,并且对回复和属性信息之间的一致性关系进行了人工标注。在此基础上,我们提出了一个键值对结构信息增强的BERT模型来识别回复的属性一致性。该模型的准确率相较于强基线模型获得了显著的提高。更进一步,我们在两个下游任务上验证了属性一致性识别模型的效果。实验结果表明,属性一致性识别模型有助于提高开放域对话回复的一致性。
2. 背景:对话生成 VS 对话理解
开放域对话生成任务旨在根据根据对话历史生成连贯、合理、有趣的对话回复[5]。由于传统的对话生成往往缺乏一致的角色特征,近几年的工作开始在对话生成中明确引入纯文本的人设描述[1]或者结构化的角色信息[2],希望提高对话回复的一致性。虽然现有的角色化对话生成模型已经能够很好地融合给定的人设、角色信息,但是这些生成模型仍然无法有效地理解对话回复的一致性关系。下面的例子展示了这一问题。

图1 理解对话回复中的一致性
在图1中,左边部分是对话系统预设的角色信息,该信息是以结构化键值对(key-value pairs)的形式给出的;右边部分是一个对话片段,包括一句对话输入和若干对话回复。在这些对话回复中,虽然R1和R2都包含了给定的地点词“北京”,但是这两个回复关于位置信息的含义却完全不同:R1表达了欢迎其他人来到自己所在地的含义,暗示了说话人现在正位于北京;而R2表达出了希望能够去一次北京的含义,因此可以推断出说话人不可能在北京。对于人类而言,理解这些一致性关系是很自然的;对于机器而言,现阶段它们仍然难以理解这些关系。现有的角色化对话生成模型已经能够结合给定的人设、角色信息较好地生成类似R1 和R2的回复;准确理解一致性关系的能力已经成为了进一步提升对话一致性的关键瓶颈。
3. KvPI数据集
针对上述问题,我们构建了一个大规模的中文人工标注数据集KvPI。该数据集的一条基本数据元组包含了键值对角色信息,单轮对话输入-回复对,领域信息,人工抽取的对话回复角色信息以及人工标注的角色一致性标签。考虑数据收集以及公开信息等诸多因素,我们在角色信息中引入了性别、地点和星座三种常见的基本属性。同时,为了在有限的三种属性内获得尽可能丰富的表达方式,我们从新浪微博收集了原始的待标注数据。人工标注过程由一组全职的标注人员进行,标注过程持续了约4个月时间。在最终的KvPI数据集中,我们总共收集到了118540条数据。
表1 KvPI数据集示例

表1是KvPI数据集的一些例子。这里的一致性关系包括三类:一致(Entailed),矛盾(Contradicted)和无关(Irrelevant)。其中,一致和矛盾都是针对说话者自身的属性而言的;如果包含属性信息但是非说话人的属性,则会被标注为无关。KvPI数据集的构建使得有效训练对话一致性识别模型成为可能。KvPI数据集以及模型、代码等资源已经全部开源在GitHub项目中。
4. 实验:KvBERT模型
虽然BERT模型在自然语言理解任务上表现突出,然而,结构化的角色信息却几乎不会出现在普通BERT模型的预训练语料中。因此,如果使用BERT模型直接线性表示键值对结构信息会难以避免地导致信息损失。我们观察到,结构化的角色信息有着固定的层次化依赖关系。比如:女性会定义性别的含义,北京会定义地点的含义,狮子座会定义星座的含义;而性别,地点,星座又会进一步定义角色信息的含义。图2中右边的结构展示了这个例子。
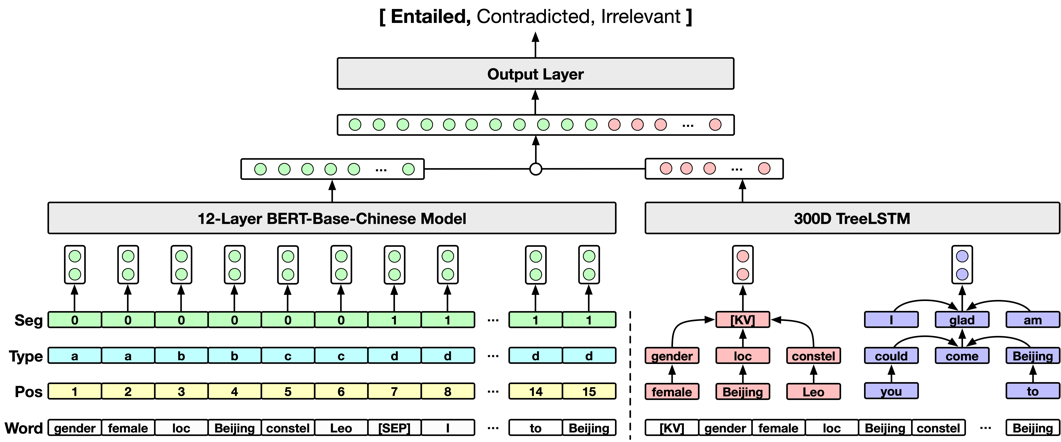
图2 用于一致性识别的结构信息增强BERT模型
为了有效建模这种结构信息,我们使用了treeLSTM来学习这种结构表示。最终,来自BERT模型的语义表示和来自treeLSTM的结构表示会进行拼接并送入输出层,以预测最后的一致性关系。
我们在KvPI数据集以及其中的各个子属性上进行了大量的实验,以充分验证模型的一致性识别能力。和已有的工作类似,我们使用准确率(accuracy)作为主要评价指标。同时,我们也计算了每一个一致性类别下的f1-score作为模型能力的细致化度量。基线模型方面,我们选取了从统计方法、循环神经网络方法到最新的预训练模型中具有代表性的若干模型。
表2 一致性识别实验结果。结果为 3次最好结果的均值,括号为方差1e-4。
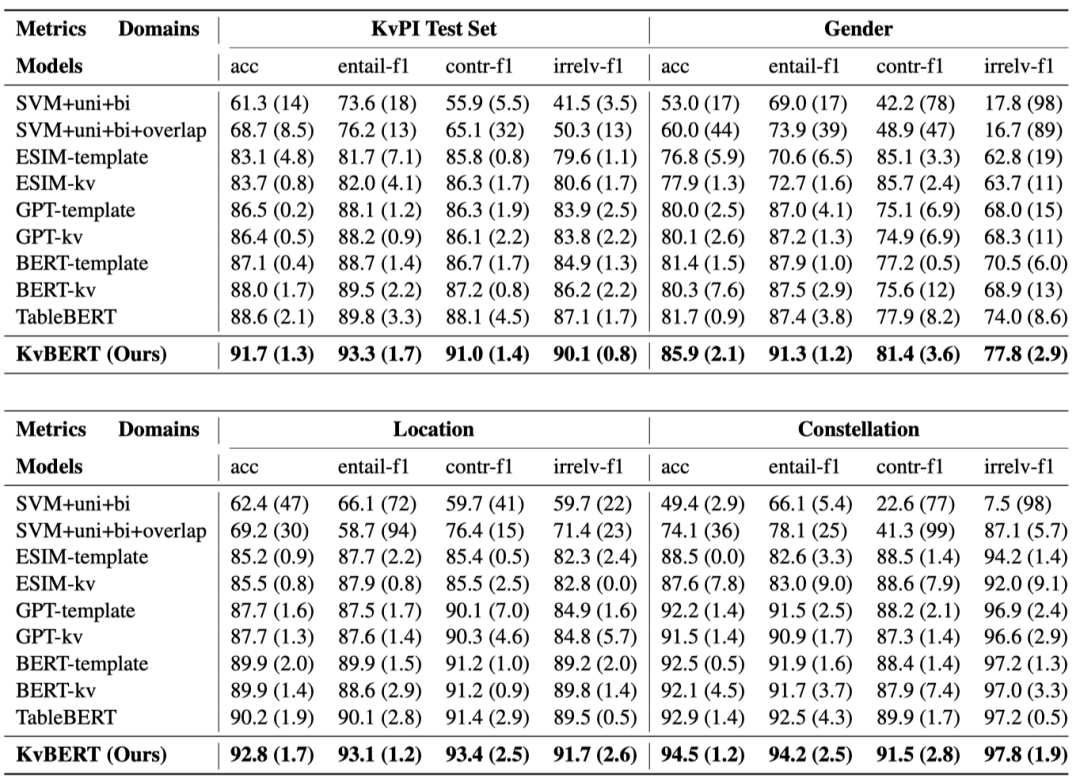
表2展示了主要的实验结果。我们的模型相较于强基线模型,仍然取得了很好的实验结果。结果验证了建模结构信息所带来的收益,同时也展示了一致性识别任务所能达到的最好效果。
5. 下游任务验证
为了进一步验证一致性识别模型的效果,我们在两个下游任务上进行了实验:I. 对检索结果进行重排序,观察重排序前后对话回复的一致性是否提高[6];II. 对生成结果进行一致性评估,并与人工评价进行对比,观察一致性识别模型的预测结果与人工评价的相似度[7]。由于篇幅限制,该部分实验的相关细节请参考我们论文的5.3节。最终的实验结果表明,一致性识别模型通过重排序能够有效降低矛盾回复的比例,并在可能的情况下提高一致回复的比例,从而提高了对话一致性;同时,即使是在生成的对话回复上,一致性识别模型仍然与人工评价的结果保持了较高的相似度。
6. 总结
在这项工作中,我们希望赋予对话系统理解对话回复属性一致性的能力。为此,我们构建了一个大规模的人工标注数据集KvPI,并设计了键值对结构信息增强的BERT模型用于一致性识别。大量的实验结果证明了我们方法的有效性。更进一步地,我们在两个下游任务上验证和展示了一致性识别模型如何辅助传统的对话模型。我们相信KvPI数据集能够帮助未来的工作更好地研究开放域对话中属性一致性的问题;同时,由于KvPI数据集提供了单轮对话及对应的一致性标注信息,从而为利用对话理解模型辅助对话生成模型的相关研究提供了数据平台。
7. 参考文献
[1] Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018. Personalizing dialogue agents: I have a dog, do you have pets too? ACL.
[2] Qiao Qian, Minlie Huang, Haizhou Zhao, Jingfang Xu, and Xiaoyan Zhu. 2018. Assigning personality/profile to a chatting machine for coherent conversation generation. IJCAI.
[3] Haoyu Song, Wei-Nan Zhang, Yiming Cui, Dong Wang, and Ting Liu. 2019. Exploiting persona information for diverse generation of conversational responses. IJCAI.
[4] Haoyu Song, Yan Wang, Wei-Nan Zhang, Xiaojiang Liu, and Ting Liu. 2020. Generate, delete and rewrite: A three-stage framework for improving persona consistency of dialogue generation. ACL.
[5] Oriol Vinyals and Quoc Le. 2015. A neural conversational model.
[6] Nouha Dziri, Ehsan Kamalloo, Kory Mathewson, and Osmar Zaiane. 2019. Evaluating coherence in dialogue systems using entailment. ACL Workshop on Widening NLP.
[7] Sean Welleck, Jason Weston, Arthur Szlam, and Kyunghyun Cho. 2019. Dialogue natural language inference. ACL.
本期责任编辑:丁 效
本期编辑:彭 湃
『哈工大SCIR』公众号
主编:车万翔
副主编:张伟男,丁效
执行编辑:高建男
责任编辑:张伟男,丁效,崔一鸣,李忠阳
编辑:王若珂,钟蔚弘,彭湃,朱文轩,冯晨,杜佳琪,牟虹霖,张馨
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至yun.he@aminer.cn!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

◎直播回放:
https://www.bilibili.com/video/BV175411A7BA?share_source=copy_web
(点击“阅读原文”下载本次报告ppt)